Regulacijom do digitalnog suvereniteta
Postoji jedna neugodna istina koju u Bruxellesu nerado izgovaraju naglas: ne možete propisati ono što niste izgradili. A Europa upravo to pokušava.

Danas se često spominje deep learning, a deep learning nije ništa drugo nego strojno učenje s dubokim (višeslojnim) umjetnim neuralnim mrežama. Neuralne mreže su bile jako popularne osamdesetih zato što je tada izumljen algoritam za njihovo uspješno treniranje (ulančavanje unazad, eng. backpropagation), ali one su nastale 1943. iz olovaka Waltera Pittsa i Warrena McCullocha kao jedna teorija filozofijske logike koja je trebala biti formalni logički sustav koji pojednostavljeno opisuje kako ljudski neuroni uče. Iz ovog je izraslo polje pod nazivom kibernetika (čije ispravno značenje i opseg bitno drugačije od onog kako se ime te znanosti koristi u pop-kulturi i svagdašnjem govoru).
Pogledajmo kako neuralne mreže izgledaju. U ovoj kolumni ćemo ilustrirati plitke neuralne mreže, odnosno neuralne mreže koje imaju samo jedan skriveni sloj, a druge varijante ćemo prikazati u nadolazećim kolumnama.
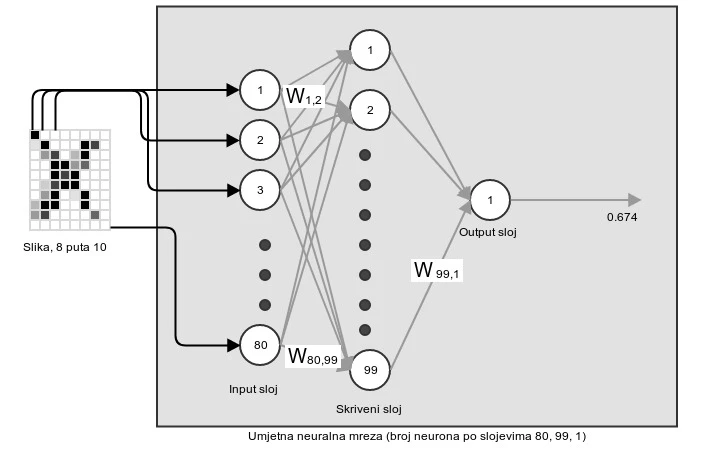
Slika 1 prikazuje shematski prikaz plitke neuralne mreže. Ideja je da mreža ima jedan input sloj, koji prima ulazne podatke koji mogu biti isključivo numerički vektori (odnosno n-torka brojeva). Ako želimo staviti bilo što drugo, moramo se snaći i smisliti način da to što želimo možemo reprezentirati kao numerički vektor. Svi input podatci trebaju imati jednaku dimenziju. Ako na primjer obrađujemo crno-bijele slike od 8 puta 10 pixela, sve slike moraju biti takve, a njihova veličina nam diktira veličinu input sloja, koji onda mora imati 80 neurona.
Kada želimo utrenirati neuralnu mrežu da prepoznaje npr. slovo X na slikama širine 8 pixela i visine 10 pixela, trebamo imati skup trenining slika, od kojih neke sadrže X a druge sadrže nešto drugo (npr. druga slova). U ovoj varijanti treniramo mrežu da prepoznaje X, odnosno želimo mrežu utrenirati tako da daje kao output 1 kada prepozna X na nekoj novoj slici, a 0 u ostalim slučajevima. Vrijednosti koje želimo kao output diktiraju strukturu output sloja, što znači da u našem slučaju imamo samo jedan neuron u output sloju, i ako je njegova vrijednost iznad 0.5, onda se smatra da je output 1, a ako je ispod onda je 0. Kada bismo npr. željeli prepoznati iz slike brojeve od 0 do 9 (taj se skup podataka zove MNIST), onda bismo imali deset neurona u output sloju, prvi bi predstavljao 0, drugi 1, itd. i kao "konačan" odgovor bi se uzeo onaj koji ima najveću vrijednost (kolika god ona bila).
Time smo objasnili dva od tri sloja, što nas ostavlja sa skrivenim slojem. Broj neurona u skivenom sloju odabire kreator neuralne mreže (mi smo odabrali 99 neurona), i postoje neke eksperimentalne heuristike za njihov odabir, ali ne ništa u vidu strogih pravila. U principu što ih više, to je mreža bolja, ali i sporija za utrenirati.
Ovime smo došli do pola objašnjenja neuralne mreže. Ono što nam fali je koncept težine ili pondera (eng. weights). Ideja je da oni kontroliraju koliko se ulazne vrijednosti prosljeđuje u sljedeći sloj. Uočimo da su svi neuroni prethodnog sloja povezani sa svim neuronima sljedećeg sloja, ali jačina te veze je determinirana težinama. Početne se težine uzimaju nasumično (radi jednostavnosti zamislimo da su nasumične vrijednosti između 0 i 1), a cijela je poanta mreže naučiti kako ih izmjeniti da mreža radi (klasificira) dobro ono što želimo.
U plitkim mrežama imamo dva skupa pondera: one između input sloja i skrivenog sloja, i one između skrivenog i output sloja. Zamislimo umjetnu neuralnu mrežu s dva input neurona, tri skrivena i jednim output neuronom. Tada imamo dva inputa u mrežu, X1 i X2. Osim toga, moramo napraviti tri ulazne vrijednosti, po jednu za svaki neuron u skrivenom sloju. To znači da nam treba šest pondera: W11, W12, W13, W21, W22, W23. Ako uzmemo Wnm, n označava redni broj neurona (odozgo prema dolje) input sloja, a m redni broj neurona u skrivenom sloju. Input za neuron 3 u skivenom sloju će biti S(X1*W13+X2*W23), pri čemu je S( ) sigmoidna funkcija, odnosno funkcija koja će bilo koju vrijednost pretvoriti u vrijednost između 0 i 1. Svi ostali neuroni će funkcionirati na identičan način.
Uočimo da ovu pricu možemo jednostavno prikazati kao matrično množenje. X1 i X2 možemo prikazati kao matricu s dva retka i jednim stupcem, a W-ove kao matricu s dva retka i tri stupca. Označimo ove matrice s X i W. Tada trebamo dobiti matricu A, koja ima tri retka i jedan stupac i svaki redak predstavlja ulaz u jedan neuron skrivenog sloja: A=S((XTW)T). Na identičan se način računaju sve vrijednosti kroz mrežu. Matrični prikaz je važan jer je on računalno vrlo brz, a stvari su se tako poklopile da je izračun vrijednosti u mreži identičan izračunu umnoška matrica, pa se zato ova metoda obilno koristi da bi se doskočilo sporosti treniranja.
Time je objašnjen prolaz unaprijed (eng. forward pass), no sada nam ostane utrenirati pondere. Glavna ideja je da se greška kasnijih slojeva sastoji od pogrešaka u tom sloju i pogrešaka u prehodnim slojevima (loši W-ovi u tom sloju, i potencijalno loši A-ovi iz prethodnog sloja). Ovaj se pristup naziva ulančavanje unazad (eng. backpropagation), i u stvari je metoda nalaženja i korekcije grešaka u ponderima, odnosno optimizacije pondera.
Premda je potpuno objašnjenje ulančavanja unazad poželjno, nemamo dovoljno mjesta u ovoj kolumni, pa čitatelja ostavljamo s intuicijom ali i ohrabrujućom informacijom da večina programskih jezika ima već gotove pakete za ovaj najosjetljiviji dio procesa učenja neuralnih mreža. Detalji izračuna se mogu naći u bilo kojem uvodu u neuralne mreže ili duboko učenje.

Postoji jedna neugodna istina koju u Bruxellesu nerado izgovaraju naglas: ne možete propisati ono što niste izgradili. A Europa upravo to pokušava.

Sigurnosni istraživači igraju iznimno važnu ulogu u modernom digitalnom društvu. Zahvaljujući njihovom radu svakodnevno se otkrivaju ranjivosti koje bi u suprotnom mogle biti iskorištene za krađu podataka, prijevare ili prekid poslovanja. Međutim, posljednjih godina sve češće svjedočimo situacijama u kojima se nakon otkrivanja sigurnosnog propusta postavlja pitanje: radi li se o odgovornom istraživanju ili o neovlaštenom pristupu sustavu?

Paušalni obrt privlači vrlo različite ljude jer tu su razni freelanceri, IT stručnjaci, konzultanti, dizajneri, novinari, fotografi i svi oni koji žele dodatno raditi uz stalno zaposlenje u njemu su pronašli istu privlačnu kombinaciju: mogućnost samostalnog određivanja cijene rada, jednostavniju administraciju, unaprijed poznate porezne obveze i mogućnost rada s više klijenata istodobno. No upravo rast broja takvih obrta otvorio je i važno pitanje: je li riječ o stvarnom malom poduzetništvu ili se paušalni obrt sve češće koristi kao zamjena za klasični ugovor o radu?















